Tutorial 1: Introduction
![]()
Introduction
Online virtual worlds have become fairly popular with the advent of global internet access. Previously they were text based simulations that were limited to universities. Currently they have become highly advanced 3D online simulations that allow millions of users to simultaneously interact in virtual environments.
One of the most interesting things about online virtual worlds from a programming perspective is that they need to be designed in a very unique fashion. They are incredibly different from the majority of applications due to the fact that thousands of people are using the same software simultaneously over an unreliable network. All of this needs to be taken into account and the design has to revolve around these concepts which forces you to write and design the software differently from what you would generally be used to.
There is a significant amount of information about the implementation and operation of some of the current and past online virtual worlds, however you will find only small pieces at a time and have to spend a significant amount of time searching for all the pieces to put together a global picture of how to implement one yourself. This tutorial series will cover the complete implementation details of how to build your own online virtual world.
As building a complete online virtual world can be fairly complex I will cover just the basic implementation details and leave the optimization and customization up to you. This way you can see how each part works clearly without the obfuscation of overly complex code. For example I will show you the absolute minimum setup for network code but then advise you to add encryption, prioritization, and so forth in your own project. As well I won't cover how to do bump mapping, 3D sound, and anything else I have covered in a previous tutorial on this site, these tutorials will only deal with online virtual world implementation details.
Cube World
For this tutorial series what I did was I first built a small online virtual world called Cube World. It is a single zone world that has some artificially intelligent cubes roaming around. It allows you to connect and roam around and interact with the other cubes and online users in the world. With the virtual online world in place I then broke the code contents into sections to cover how the entire project works in logical pieces.
The reason I used cubes was for simplicity as I am just covering the basic implementation details and will leave it up to you to place more advanced entities in the world as it suits your application. You will also notice that only the bare minimum in terms of chat, movement, and interaction are implemented, once again this is to make the tutorial series as simple as possible but allow you to move into a more advanced implementation yourself.
To begin the tutorial we will now discuss how the basic architecture of an online virtual world works.
Client-Server Architecture
Online virtual worlds use a specific type of architecture called client-server. What this means is that users run our client software on their own computer and then connect and process over a network to a server that is running the server portion of the software that we have written. The most basic setup is a single client connecting to a single server over a network:

Online virtual worlds are usually much larger in scope and generally have a minimum of several thousand users connecting over a high speed network to a large server farm:
We will now discuss the two sides of the architecture called client-side and server-side.
Client Side
The client-side of the application runs the client software that we have written for the user on their computer. The client software is usually uniform for all clients connecting. Once in a while we may allow different client software such as a super user administration application to connect or a customer service client. But for all other clients they should be running the same type and version of software so they can interact with the online virtual world in the same manner without versioning issues.
The client software does very little processing in relation to the online virtual world. Put simply it is only a window to the virtual world which accepts users input and makes requests to the server. Otherwise it is just graphically simulating what happens in the virtual world with relation to this specific client's view into that virtual world.
Some past and current online worlds off-load certain important calculations to the client software but this is a big mistake. Everything that is done on the client-side can be seen and modified by anyone with a basic programming background. And always remember that there are numerous people with very advanced computer backgrounds that can write easy to use tools for automating at a high speed many user driven tasks in the virtual online world. To keep your online virtual world egalitarian you need to eliminate this threat by not implementing anything in the client that affects the online world in any manner whatsoever. There are some exceptions to the rule such as advanced physics, but it is up to you to ensure the server double checks this using a simpler model or you need to remove said physics from your online world to ensure it can't be hacked. Remember that when other users find out there are hacks available and people are using them they will lose respect, immersion, and often interest in your product.
The Cube World client is written using C++ with DirectX 10 as the graphics API. I use C++ and DirectX for reasons of speed and responsiveness. Now with the exception of using C for the programming language and OpenGL as the graphics API nothing else should be used for writing a client for a 3D online virtual world. The remainder of languages and graphics APIs just don't perform on the same level for this type of application. If you are interested in writing a virtual online world but it will not be used for production purposes and never go live then it is fine to use something else just for learning purposes.
In the Cube World client you will notice that 80% of the code is just graphics code. Input, audio, networking make up the rest. There is very little application code as that all sits on the server-side part of the application. As stated before the client side is just a window that accepts user input.
Server Side
The server-side code is where 100% of the online virtual world processing occurs. No processing is done on the client, everything that happens in the world is processed here and messages are sent out to all the clients to keep their view into the world up to date. The server-side software has been written in C++ on the Linux operating system, and you will find most of the current online virtual worlds use this combination.
Physically and logically the server-side software is split into different groups of servers that perform the different functions needed for an online virtual world. The implementation of the server-side environment can be very simple with just a single physical server running all the software needed. And on the other hand it can be incredibly complex using traffic load balancers, multiple disaster recovery sites, high availability multi-node clusters for each server, and so forth.
Now the specifics of how to break the servers into different types depends on the application. Some online worlds use a seperate physics server to do all line of sight calculations and such. Some center processing around the activity of the users and only do calculations based on actors and what can be seen by users in the online world while shutting everything else off that is not in use. These are decisions that need to be made based on what your online virtual world is going to do. For the purposes of these tutorials I made Cube World to be persistant (nothing ever gets shut off or sits around idlely until a user comes near it) and processing is zone based so I break the servers into zones or areas and do all processing needed by that zone on the same server.
For this tutorial series I am going to cover five basic logical server types that generally every persistant online virtual world uses at a minimum. This will be a patch server, a login server, a world server, a zone server, and a database server. Also note that a database server, a zone server, and a world server could all sit on one physical server box. When we say server here we are actually just referring to separate software packages that perform a specific server based function. You can think of each as individual programs that can talk to each other and serve up their own particular type of information to clients as needed. And remember that just because only these five are discussed it does not mean that you could not create different ones. For example maybe your application is heavily dependent on physics calculations and requires a dedicated physics server. But we will try to keep things general for the purposes of this tutorial and discuss the five basic server types.
Now with these five server types a basic setup that maintains two large seperate online virtual worlds might look like the following:
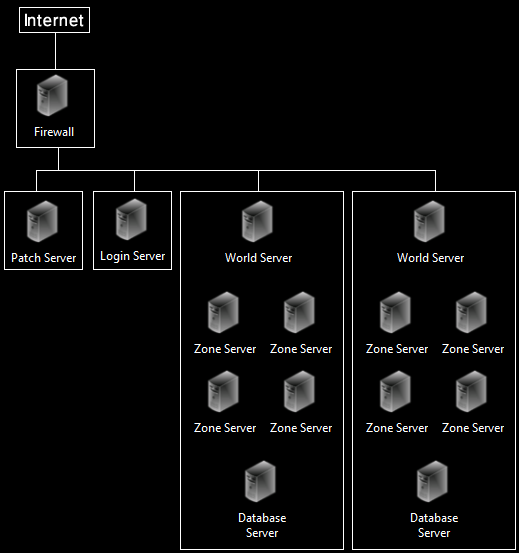
Note that the diagram is a logical setup, not physical. And although the diagram has multiple and zone, world, and database servers our implementation will be much simpler for the purpose of the tutorial, in fact the Cube World software sits on just a single physical server. Now that you see how they are logically connected lets talk about the purpose and basic function of each server type.
Patch Server
A patch server is responsible for ensuring that the client connecting to the online virtual world is using the most current version of the client software. It is also responsible for distributing the client software to users that are running an older client version or have corrupt or missing files. In simple terms this is just an FTP server dedicated to the client software for this particular online virtual world.
The implementation of patch servers varies incredibly depending on the size of the client software and the company implementing it. Everyone understands that clients don't want to wait forever to patch their software, so at a bare minimum the patch server needs very high speed disk or enough memory that the client can sit entirely in memory. There are also factors such as the location of your clients geographically, not everyone has a high speed reliable ISP providing them internet so this needs to be factored into how you implement a patch server.
The easiest way to implement a patch server is to serve the files yourself from a single server. However this falls into all the above mentioned traps that will cause user waits. The second most common way is the usage of multiple patch servers located in strategically ideal locations near the majority of the client user base, sometimes this is even outsourced to other companies that are dedicated to serving up software and already have this type of architecture in place. A final common practice is that clients are allowed to know about other clients in their area and distribute software to other nearby clients using built in software torrents. Although this sounds ideal it does break privacy laws in numerous countries and can cause your clients who may be limited to a certain network usage amount to go over their ISP set limits and have to pay a larger bill each month.
There are no perfect solutions for a patch server implementation but there are many options you can explore. With all of them you will need to write your own software to handle patching. This is generally a side program written into the client software so that when the client software is started by the user the first thing it does is check if the client is up to date. If it finds the client software is out of date it will talk to the patch server to generate a list of the files it needs to be up to date.
One last thing to note is that patch servers also often operate as the authentication servers. The client user name and password are verified here before patching. This also limits people who aren't paying for your software from using up bandwidth that you will end up having to pay for. Because the user authentication details are confirmed here the patch server requires access to a small or central database that can confirm the user credentials supplied. Most of the time this is handled by a specialized server that is also responsible for billing and so forth. Be warned that anything with credit card information will be susceptible to terrible audits from credit card companies and will need to meet the payment card industry standards which can be a serious pain. This is why you may want to separate basic authentication from the database that also contains the users payment information.
Login Server
After the user has been authenticated and has connected to the patch server and ensured their client is up to date they are then given the current IP address of the login server from the patch server (assuming they are on separate servers). They then connect to the login server which handles redirecting the user to the online virtual world. If you have multiple online virtual worlds (such as in the diagram above) then the login server can give the user the choice of which online world to connect to.
The login server software can also provide information such as where the world servers are located geographically and how many users are currently online in each one. But the primary responsibility is providing the user with the address of the online virtual world they are connecting to and also informing the server that the user will be logging in and to prepare for them. Once the user has selected the specific online virtual world to log into the login server then forwards them the IP address of that world server and the client will attempt to connect to it.
The login server also does authentication of the user. This was handled in the patch server but only to prevent un-registered users from downloading the client software. And some online virtual worlds give out the client software for free to promote people to try their world so authenication for them has to occur here in the login server. Some login servers also handle payment for online virtual worlds that charge monthly fees. They allow users to create accounts and provide credit card information. But the primary responsibility is still to provide an interface to the client to access the online world and authenticate themselves.
World Server
The world server is the manager of the online world. It is primarily responsible for coordinating the different zone servers as well as all activity between users that is not related to a specific zone (such as chat messages to users in other zones). It handles moving users between zones/regions as well. The majority of processing in an online virtual world is done in the zone servers, but the world server is what keeps track of the zones.
Other functions such as shutting down and starting up zones live is also handled by the world server. It can also handle the mail system for the world.
Some implementations also use the world server for load balancing. For example it may see that 10 zones have very low activity and move them all onto a single server since their processing load is low. And likewise it might find a zone that has a large amount of activity and move it onto its own physical server so that it can properly handle the processing amount.
So the main role of a world server is definitely that of a coordinator, but it can be extended to handle global needs of the virtual online world.
Zone Server
The zone server is responsible for all the processing for the online virtual world. This is where all activity in your virtual online world will take place. And this is also where the majority of the coding will take place.
Zone servers handle local processing for systems such as the artificial intelligence of the entities that exist in the zone, combat simulations, in-zone communication, movement/travel, zone event processing (for example weather), simplified physics, transactions, crafting/manufacturing simulations, and many more. It is entirely dependent on what your online virtual world actually simulates that will determine what the zone servers will need to process. But what it does process is localized to just that area/region inside the zone.
Most online virtual worlds break the world into multiple zones so that the processing is distributed based on the different regions/locations that exist in the virtual world. For example the image of the world below is split into 16 different zones:

To just have a single zone for the entire world would not allow you to distribute processing in a straight forward and logical manner. This would also require some very serious hardware to pull off for a busy online world. But if the world is broken into zones we can locate zones on different servers and even move them around live if need be. Where and how many zones per server will depend on the actual amount of processing that will occur in each. For example a city may be a small geographic area but it performs an incredible amount of processing and may require its own dedicated server. Whereas a huge country section around the city twenty times its size performs much less processing and can sit on a zone server that shares multiple zones.
So everything your virtual online world does will happen inside the zone servers.
Database Server
The database server contains all the metadata about your world. Everything that drives the world needs to come from the database. The names of the zones, the information about the entities in the zone, the amount of iron ore that can be mined in the zone, and so forth. Using a database also makes implementing a data-driven design very easy. You can make an update to the database and then push it to the zone live and see the effect it has.
Now some people prefer to use flat files to start but at some point you will want to move into using a database. If you don't have the time to learn the complexities of good database software such as Oracle you can use simpler open source products such as MySql which have a much easier learning and implementation curve.
Note also that the client-side software should never talk to the database directly. Only the world and zone servers should have access to the database.
Summary
So this was a basic introduction to online virtual worlds. The next tutorials in the series will take a deeper look at how things work as well as the complete implementation details of the Cube World virtual world.
![]()